Comparing methods for accessing secrets in HashiCorp Vault from Kubernetes

There are multiple ways of accessing secrets in HashiCorp Vault from your Kubernetes workloads. Which approach should you use? Well, “it depends”, so let’s cover some common approaches and where the complexity in each approach lies to help you make an informed decision.
This blog was published just before HashiCorp released their [Vault Secrets Operator](https://github.com/hashicorp/vault-secrets-operator). We have not found the time to update this comparison to include it, sorry about that.
To help the decision process for future HashiCorp Vault and Kubernetes users we decided to make a comparison of several approaches and provide an overview that you can use to help you decide.
The different approaches we compare in this post are:
- Vault REST API - using the Vault REST API directly from your workload.
- Vault Sidecar Injector - using the sidecar injector to inject secrets into your pods.
- Vault CSI Provider - using the Kubernetes CSI Secrets Store with the Vault CSI Provider.
- External Secrets Operator - using the External Secrets Operator to sync Kubernetes secrets.
- ArgoCD Vault Plugin - using the Vault plugin for ArgoCD to inject secrets in our manifests.
We will rank each approach based on three effort levels:
- Platform Effort - effort to setup requirements on cluster (e.g. operators, drivers, etc).
- Deployment Effort - effort to deploy your Kubernetes workloads that will access the secret from Vault. Essentially, how much effort is it to write the Kubernetes manifests that use the secrets.
- Application Effort - effort (if any) to update the application code to use the secret.
We decided on these three levels as we feel they closely reflect how HashiCorp Vault is used in the industry: typically a platform team manages Vault itself and defines the recommended approaches for accessing secrets while stream-aligned teams deploy their workloads that retrieve the secrets (according to the Team Topologies definition of teams). The responsibility of writing the Kubernetes manifests (i.e. the Deployment Effort) is something that varies: sometimes the platform team provide an abstraction over this, other times stream-aligned teams interact directly with the Kubernetes API. That is also something that depends on what platform you are building.
@admonition::warning::Setting up a Kubernetes cluster and HashiCorp Vault instance (as well as auth methods) was not taken into account as part of the effort, as they are prerequisites for all the methods.
If you are interested in the end results right away, here they are. Keep reading to learn about each approach and why we gave it that score. Higher values represent more work.
| Platform Effort | Deployment Effort | Application Effort | |
|---|---|---|---|
| Vault REST API | ■□□□□ | ■■□□□ | ■■■■■ |
| Vault Sidecar Injector | ■■□□□ | ■■■■■ | ■■□□□ |
| Vault CSI Driver | ■■■□□ | ■■■■□ | ■□□□□ |
| External Secrets Operator | ■■□□□ | ■■■□□ | ■□□□□ |
| ArgoCD Vault Plugin | ■■■□□ | ■■□□□ | ■□□□□ |
Besides the effort, what is also very important when choosing a secrets method is the support for Vault Secrets Engines and Vault Auth Methods. Additionally, features like synchronising to Kubernetes secrets and secrets rotation were also considered important. There are more factors to consider, but these were the ones which we believe can influence the decision quite heavily and we will discuss these a bit more at the end.
Now let us cover some of the groundwork before we get into the comparison.
Background & Problem
HashiCorp Vault is a the Open Source Swiss army knife of secrets management. It not only handles static secrets but can also act like a broker for creating dynamic, short-lived secrets on the fly. It is API-driven, meaning anything you can do via the UI and CLI, can also be achieved via a REST API. And that makes it pretty good for automatically fetching secrets, which is what we will talk about in this post.
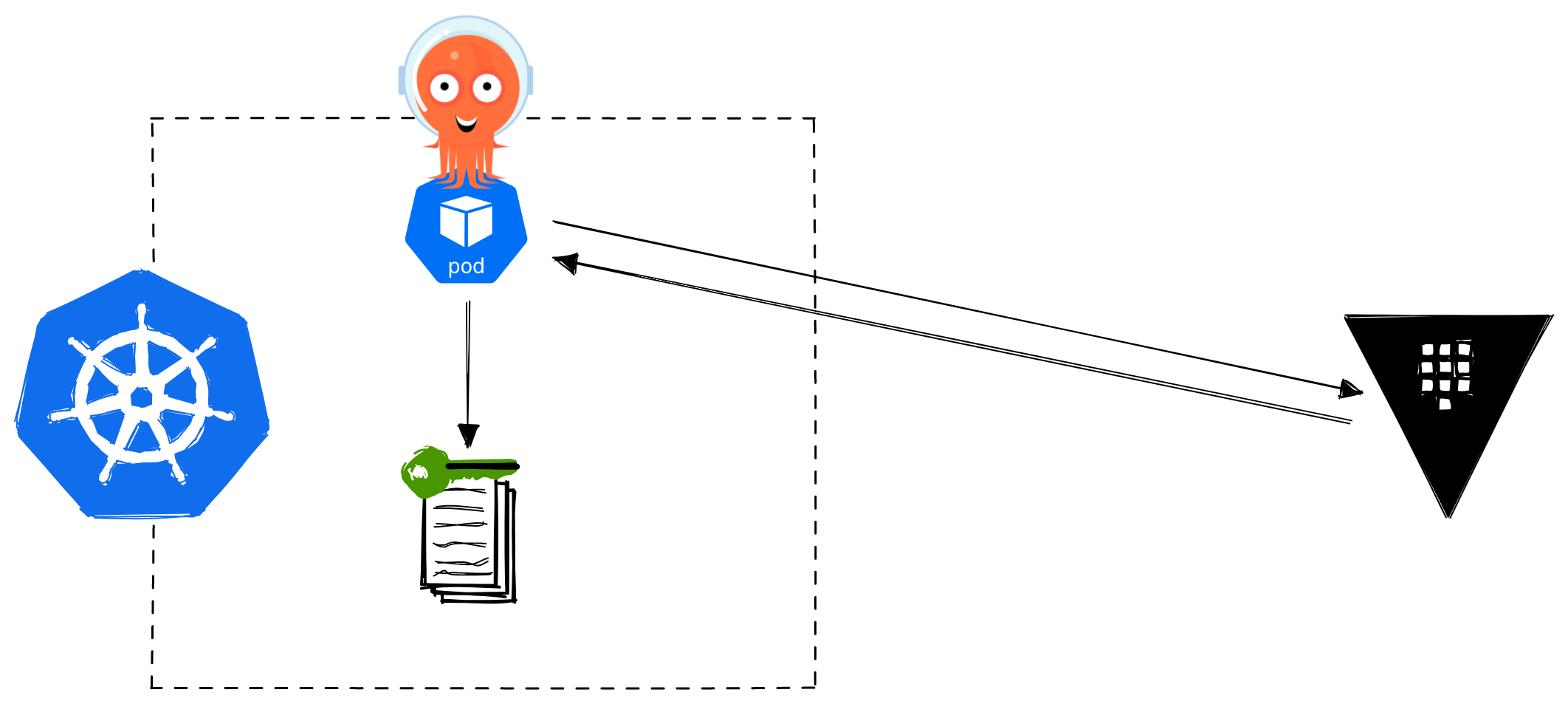
When it comes to Kubernetes, a typical use case is that we will have a pod that requires some identity (i.e. a secret) to talk with some other service that could be running anywhere.
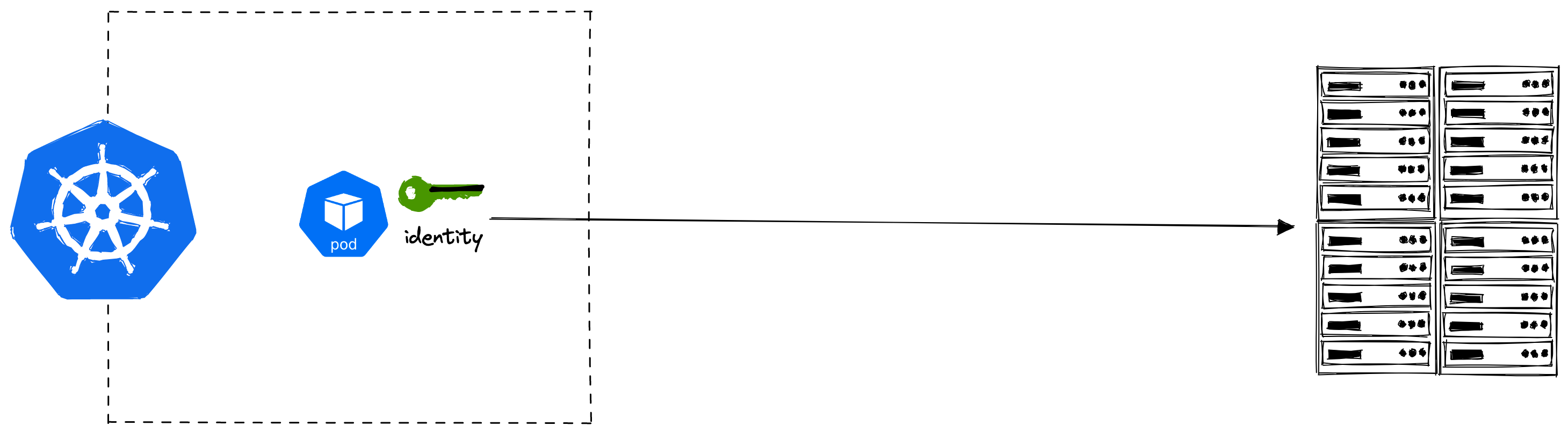
The obvious approach is to create a Kubernetes Secret object manually that our pod can use. We heavily recommend against doing this in production, as illustrated by the following diagram:
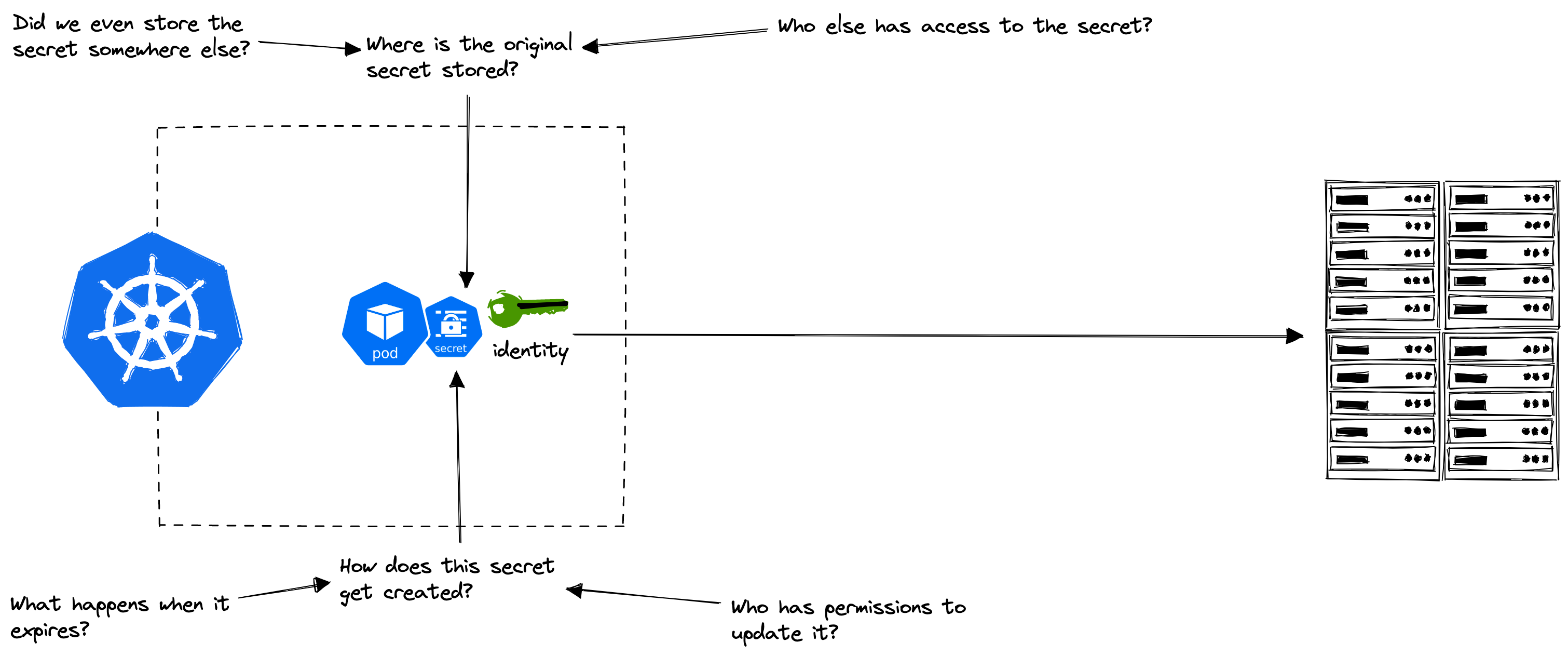
Why do we care so much about secrets?
If you don’t already take secrets management seriously, let me encourage you with just two statistics. These two statistics came from the research done by IBM on the cost of a data breach in 2022. There are, of course, more statistics out there from other research.
19%
Percentage of breaches caused by stolen or compromised credentials
243 days
Average time to identify and contain a data breach
Stolen or compromised credentials is still the #1 initial attack vector in 2022, constituting 19% of all security breaches.
Breaches caused by stolen or compromised credentials have the longest lifecycle. The longer the lifecycle, the higher the cost of the breach.
It is a really good idea to use a secrets manager that is <strong>automation-friendly</strong> to avoid secret sprawl and help prevent compromised credentials. And this is where HashiCorp Vault excels.
Our goal, therefore, is to use HashiCorp Vault to manage identities and secrets and to access these from our Kubernetes workloads. Of course not all identities should be managed this way, e.g. you could use AWS IAM Roles for Service Accounts if using EKS.

Comparison
As a recap, the approaches we will compare are:
- Vault REST API - using the Vault REST API directly from your workload
- Vault Sidecar Injector - using the sidecar injector to inject secrets into your pods
- Vault CSI Provider - using the Kubernetes CSI Secrets Store with the Vault CSI Provider
- External Secrets Operator - using the External Secrets Operator to sync Kubernetes secrets
- ArgoCD Vault Plugin - using the Vault plugin for ArgoCD to inject secrets in our manifests
Vault REST API
Vault is an API-driven tool, which means that any action you perform can be done via the REST API (the CLI and Web UI use the REST API). Therefore you can interact with the REST API directly from your application, either using a standard HTTP library or a client library of your choice. Your workload pod will then interact with the Vault REST API directly.

Vault REST API: Effort
Platform Effort: Nothing needs to be done on the platform.
Deployment Effort: The credentials you use to authenticate with Vault will need to be added to the deployment, such as creating a Kubernetes ServiceAccount or using a cloud IAM account.
Application Effort: This approach pushes all the responsibility onto the development side. Of course you can create an internal library or template project to make your approach reusable but, nevertheless, you need to code the use of Vault’s REST API.
| Platform Effort | Deployment Effort | Application Effort | |
|---|---|---|---|
| Vault REST API | ■□□□□ | ■■□□□ | ■■■■■ |
Vault REST API: Support
When using the REST API, you can do anything that Vault, your programming language, and runtime support. However, there is not built-in support for synchronising secrets to Kubernetes secrets, nor any kind of secrets rotation.
| Secrets Engines | Auth Methods | Sync to K8s Secrets | Secret Rotation | |
|---|---|---|---|---|
| Vault REST API | All | Any | No | No, not built-in |
Vault Sidecar Injector
The Vault Agent Sidecar Injector relies on pod annotations and “injects” secrets into the pod. Under the hood there is a Kubernetes Mutating Webhook Controller that modifies the pod if the vault.hashicorp.com/agent-inject: true annotation is detected. A shared memory volume is mounted and used by sidecars (init and sidecar) that fetch and can also renew the secret.

Vault Sidecar Injector: Effort
Platform Effort: The Vault Sidecar Controller must be installed on each cluster that wants to use this method.
Deployment Effort: Writing annotations on the pod will be the bulk of the work with this approach, and the annotations can be a little bit clumsy (especially as there are so many) and can take a few tries to get it right.
Application Effort: The application only needs to support reading secrets from files, which is a pretty standard approach.
| Platform Effort | Deployment Effort | Application Effort | |
|---|---|---|---|
| Vault Sidecar Injector | ■■□□□ | ■■■■■ | ■■□□□ |
Vault Sidecar Injector: Support
The Agent Sidecar Injector uses the Vault Agent under the hood which seems to support all secrets engines and all auth methods. It’s not very clear exactly what is and is not supported but the Vault Agent is quite general purpose so you would assume the support for multiple secret engines and auth methods is high.
The Sidecar Injector cannot synchronise with Kubernetes secrets. This can make it quite tricky to integrate with 3rd party tools that do not provide an easy method to read from files, or 3rd party tools where the only option you have is to provide either a command line argument or an environment variable. The community has invented several happy hacks to work around this, but you should probably look for another approach if that’s an issue for you.
| Secrets Engines | Auth Methods | Sync to K8s Secrets | Secret Rotation | |
|---|---|---|---|---|
| Sidecar Injector | All | All | No | Yes |
Vault CSI Provider
The Container Storage Interface (CSI) is a standard for exposing arbitrary block and file storage systems to containerised workloads. On Kubernetes, a CSI compatible volume driver must be deployed within a cluster and users can then interface with this through the csi volume type within a pod.
The Vault CSI Provider relies on the Secrets Store CSI Driver which allows Kubernetes to mount secrets stored in external secrets managers into pods as volumes. A Provider for a Driver for Volumes within a Storage Interface for Containers. Something like that. We are quite used to this level of abstraction by now and configuring it is not that bad.
Although the Secrets Store CSI Driver makes a volume available for pods to mount, it is also possible to sync the volume to a Kubernetes secret.
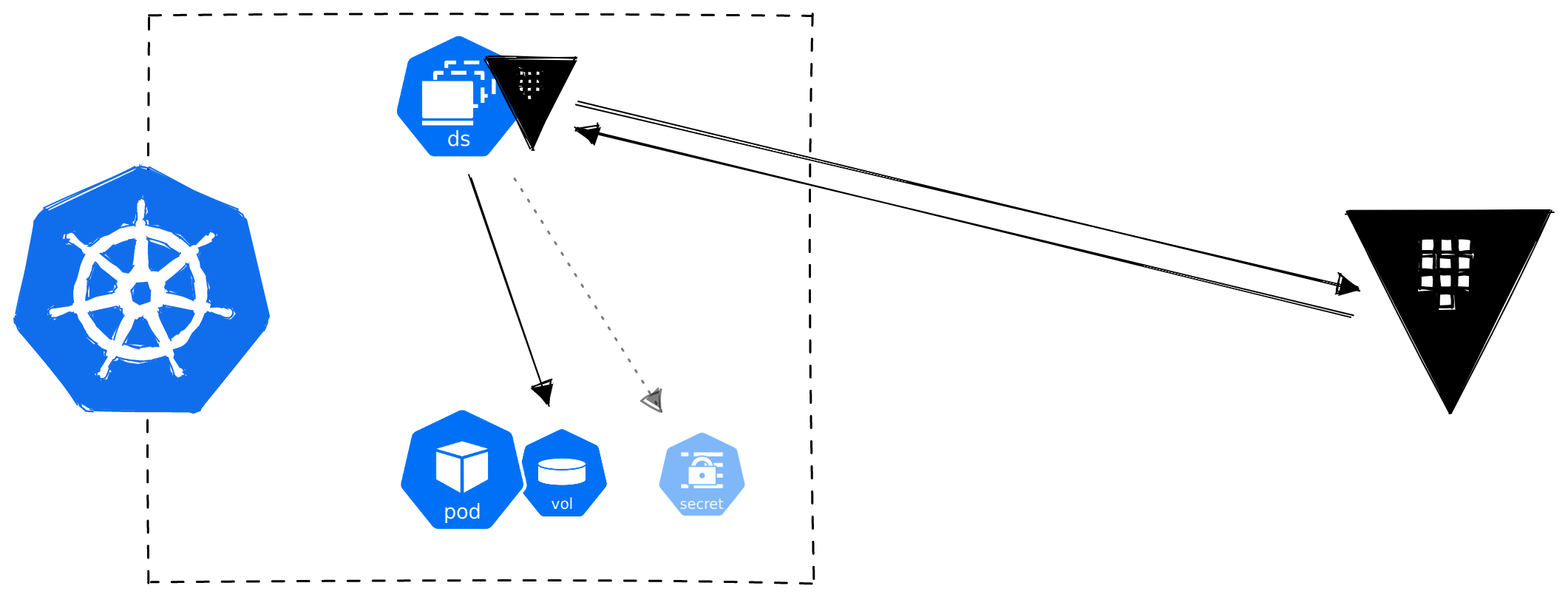
Vault CSI Provider: Effort
Platform Effort: Both the Secrets Store CSI Driver and the Vault CSI Provider need to be installed in each cluster. However, they are stateless and thus quite easy to maintain/upgrade.
Deployment Effort: The Vault CSI Provider pushes most of the work to the manifest writing. A SecretProviderClass must be created and it must be mounted into the pod. A simple example is provided by the documentation.
Application Effort: The application can read from environment variables or files.
| Platform Effort | Deployment Effort | Application Effort | |
|---|---|---|---|
| Vault CSI Provider | ■■■□□ | ■■■■□ | ■□□□□ |
Vault CSI Provider: Support
The Vault CSI Provider has a great feature set, except it only supports the Kubernetes auth engine. This might seem fine, after all this is a blog post about Vault and Kubernetes, however we have found that in a multi-cluster environment it is quite simple to use cloud IAM accounts/roles to authenticate with Vault. This is mainly because the Vault Kubernetes auth method requires that each Kubernetes cluster have its own auth engine from which ServiceAccounts can authenticate.
| Secrets Engines | Auth Methods | Sync to K8s Secrets | Secret Rotation | |
|---|---|---|---|---|
| Vault CSI Driver | All | Kubernetes only | Optional | Yes, if using files |
External Secrets Operator
The External Secrets Operator is a Kubernetes Operator (Controller + CRDs) that synchronises ExternalSecret Custom Resources with Kubernetes Secrets. ExternalSecret resources reference a SecretStore, of which you have many to choose from (AWS Secrets Manager, Azure Key Vault, Google Secret Manager, GitLab Variables). You can even sync Kubernetes secrets across clusters. And of course, HashiCorp Vault is supported.
In our experience, this seems to be a very popular method of getting secrets out of Vault and into Kubernetes, and the attraction is that it is very easy and is decoupled from the workloads (for better or for worse). Hence in the below diagram our workload pod is nowhere to be seen because it is not needed.
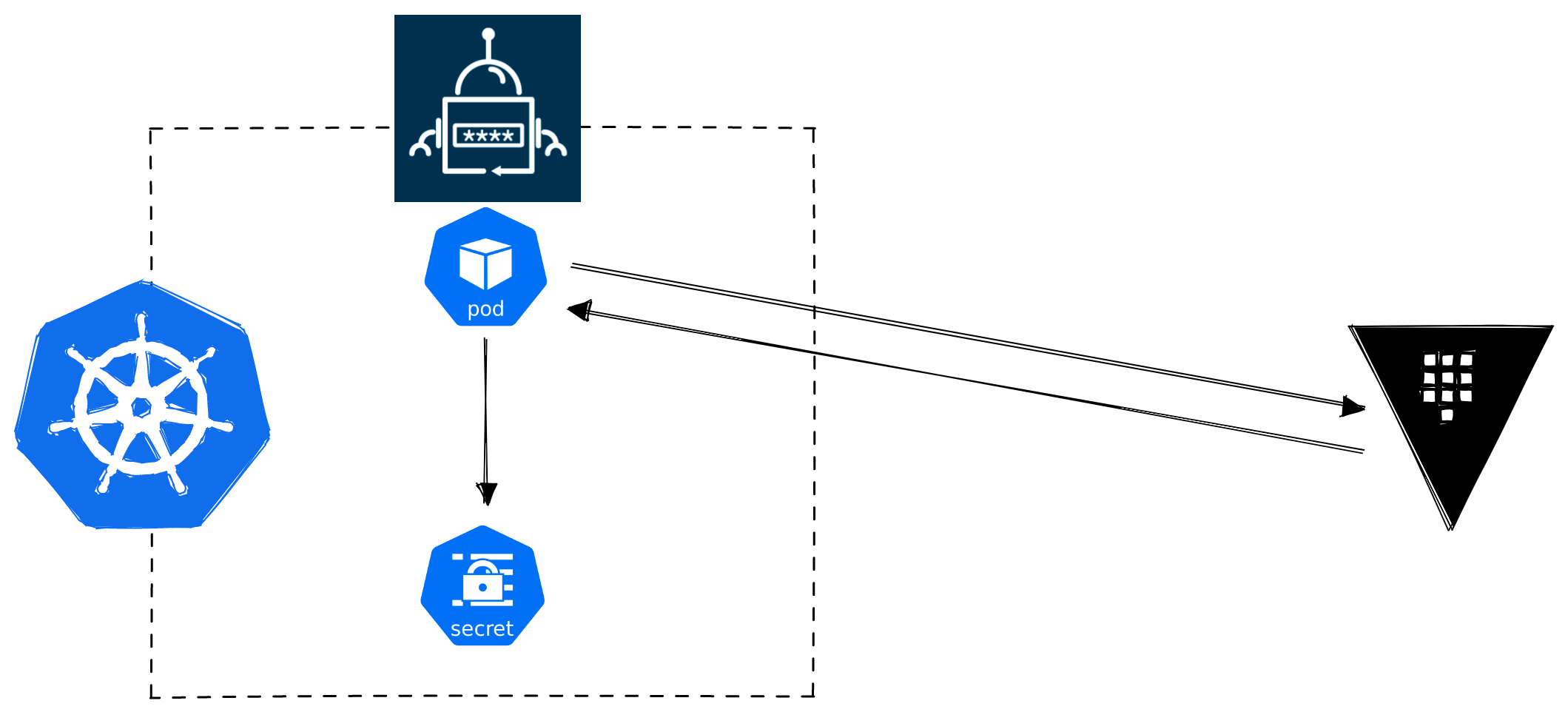
External Secrets Operator: Effort
Platform Effort: The External Secrets Operator must be deployed to each cluster. It is very easy to deploy and maintain.
Deployment Effort: Writing the manifests is quite straight forward. Two custom resources are needed to sync the secret (SecretStore and ExternalSecret) and then the Kubernetes secret can be referenced in whatever manner you wish from your workload.
Application Effort: The application can read from environment variables or files.
| Platform Effort | Deployment Effort | Application Effort | |
|---|---|---|---|
| External Secrets Operator | ■■□□□ | ■■■□□ | ■□□□□ |
External Secrets Operator: Support
The External Secrets Operator is limited to only supporting the KV store. Which is interesting considering how popular it is and how there is so much talk about dynamic secrets these days. It begs the question: how many people actually use dynamic secrets? There is also a quite limited selection of auth methods. As with the Vault CSI Provider, when working with multi-cluster environments it can be easier to work with cloud IAM accounts/roles instead of having to mount each Kubernetes cluster as its own Vault auth method.
| Secrets Engines | Auth Methods | Sync to K8s Secrets | Secret Rotation | |
|---|---|---|---|---|
| External Secrets Operator | KV only | Token, AppRole, Kubernetes, LDAP, JWT/OIDC | Yes | Yes, if mounted as file |
ArgoCD Vault Plugin
The ArgoCD Vault Plugin requires that you use ArgoCD for managing your Kubernetes deployments. It is the only method in our list that has any kind of dependency on tooling (other than Vault itself), but it is quite an elegant approach and ArgoCD is very popular so we figured it should be included.
The plugin works by templating placeholders in Kubernetes manifests with secrets read from secrets managers (like HashiCorp Vault, though others are supported as well). Obviously you do not want to put your sensitive values straight into Kubernetes objects which are not made for storing sensitive values, so, likely, your sensitive values are templated into Kubernetes secrets. However, this does mean if you store non-sensitive values in Vault (e.g. cloud resource IDs, or other configurations), then you could template those directly into your Kubernetes manifests. This is a fairly opinionated topic, so let’s say that “it depends” whether that’s a good thing or not, but it’s an interesting side effect that solves many common problems with passing values from infrastructure tools like Terraform to your Kubernetes manifests.
ArgoCD Vault Plugin: Effort
Platform Effort: (Assuming you already have ArgoCD) This requires installing the plugin, for which the traditional approach is deprecated, and the newer sidecar-based approach is recommended and much more maintainable.
Deployment Effort: Writing the manifests can be a bit clumsy to get right but the ArgoCD UI makes it quite clear when something did not work, which helps a lot. Additionally, because you are templating raw Kubernetes manifests, it is also very easy to check that everything went as intended.
Application Effort: The application can read from environment variables or files.
| Platform Effort | Deployment Effort | Application Effort | |
|---|---|---|---|
| ArgoCD Vault Plugin | ■■■□□ | ■■□□□ | ■□□□□ |
ArgoCD Vault Plugin: Support
The ArgoCD Vault Plugins support is very similar to that of the External Secrets Operator. Therefore many of the same points/questions apply.
| Secrets Engines | Auth Methods | Sync to K8s Secrets | Secret Rotation | |
|---|---|---|---|---|
| ArgoCD Vault Plugin | KV only | AppRole, Token, Github, Kubernetes and Userpass | Optional | Manual |
Wrapping up
When considering the effort involved in the different approaches, it is important to consider your context. Are you a small, highly connected team, or are you a big enterprise with dedicated platform teams? In the former case, perhaps it does not matter where the effort is placed as long as the solution enables secure secret access without adding waste to the software delivery. In the latter case, it should be a goal to pay the effort by the platform team to enable stream-aligned teams to securely access their secrets with minimal effort. After all, there will be many more stream-aligned teams than platform teams so the approach should scale favourably.
| Platform Effort | Deployment Effort | Application Effort | |
|---|---|---|---|
| Vault REST API | ■□□□□ | ■■□□□ | ■■■■■ |
| Vault Sidecar Injector | ■■□□□ | ■■■■■ | ■■□□□ |
| Vault CSI Driver | ■■■□□ | ■■■■□ | ■□□□□ |
| External Secrets Operator | ■■□□□ | ■■■□□ | ■□□□□ |
| ArgoCD Vault Plugin | ■■■□□ | ■■□□□ | ■□□□□ |
When considering the features of the various approaches, we encountered a few things that helped guide our decisions:
- Third party tools. If you manage a lot of 3rd party tools on Kubernetes you might find it quite painful to try and use an approach that does not support synchronising with Kubernetes secrets. Sadly not all tools support sane approaches for reading secrets, or those methods are not well exposed or documented. Moreover, if you rely on Helm for your deployments, you will likely find great inconsistency and sometimes clear lack of support for accessing secrets in certain ways. This can become a constant point of friction and might make the decision easy: sync to Kubernetes secrets.
- Scalability. If you work with multi-cluster setups each cluster will need access to Vault. This can become a configuration pain if using the Kubernetes Auth Method with Vault, as each cluster needs its own auth engine. Sure, you can automatically add each cluster as an auth method when you create it (e.g. with Terraform), but the real pain is when using the auth method in your Kubernetes manifests as you need to provide the unique name of the auth method. Suddenly your workloads are cluster-aware. Using cloud IAM accounts can therefore be favourable, but the support for cloud IAM auth methods is more limiting.
- Secrets rotation. If you use dynamic secrets and there is a chance your workload could fail to authenticate once the secret expires, then secrets rotation should be considered.
- Multi-cloud with cross-cloud access. Dynamic secrets should be high on the agenda so that, for example, a pod in one cloud can get dynamic credentials for an IAM account in another cloud. Many of the approaches only support key-value secrets from Vault.
Here is a summary of the different approaches and their support.
| Secrets Engines | Auth Methods | Sync to K8s Secrets | Secret Rotation | |
|---|---|---|---|---|
| REST API | All | Any | No | No, not built-in |
| Sidecar Injector | All | All | No | Yes |
| Vault CSI Driver | All | Kubernetes only | Optional | Yes, if using files |
| External Secrets Operator | KV only | Token, AppRole, Kubernetes, LDAP, JWT/OIDC | Yes | Yes, if mounted as file |
| ArgoCD Vault Plugin | KV only | AppRole, Token, Github, Kubernetes and Userpass | Optional | Manual |
In our experience, centrally managing secrets and providing an efficient yet secure way to access them, is something that requires thorough consideration and some testing. Secrets management is neither particularly easy nor particularly difficult, but it is work that needs to be done. This is an area where platform teams have a significant role in helping to secure our clouds and workloads, whilst enabling stream-aligned teams to work with the abstraction provided without adding to their cognitive load.
These are our findings and our conclusions. If you disagree with them, why not reach out to us and let us know why. Or if you found something particularly insightful, leave us a comment! Additionally, if you’d like any help with HashiCorp Vault and Kubernetes please get in touch!