Demystifying Service Level acronyms and Error Budgets

Availability, fault tolerance, reliability, resilience. These are some of the terms that pop up when delivering digital services to users at scale. Acronyms related to Service Levels tend to pop up as well. Most developers have at least seen SLA, SLO and SLI and some even know what they mean. However, based on personal experience, not many people who work in the intersection of writing, delivering and maintaining software necessarily know how to make use of them in their software delivery process.
In this fundamental level blog post I will explain what different Service Level concepts mean and how to use them effectively in the software delivery process.
I also did a talk at DevOps Finland on this topic, Service Levels, Error budgets, and why your dev teams should care.
What is a Service Level and why does it matter?
Depending on the source, I have seen claims that anywhere from 40% to a whopping 90% of a software systems lifetime costs consist of operational and maintenance costs, making the development costs of the software pale in comparison. Additionally, costs of even short service breaks and unplanned downtime are significant and getting more expensive still. This goes to show that being able to maintain your service availability and preferably being able to preemptively react to service degradation is not just a matter of convenience, but carries a very real price tag with business consequences.
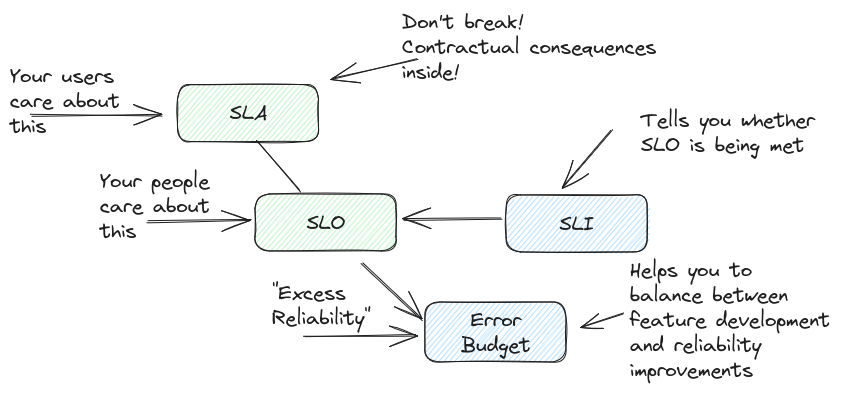
Service Level embodies the overall performance of your software system. It consists of goals that, when met, indicate that your system is performing at the desired level, and measurements which tell if those goals are being met, exceeded or if the system is underperforming. There are three distinct concepts associated with the Service Level: Service Level Agreement (SLA), Service Level Objective (SLO) and Service Level Indicator (SLI).
Service Level Agreements
Service Level Agreements are the base level of performance and functionality you promise to your users, be those paying customers or developers using your internal tooling platform and databases. Typically SLAs are seen to relate to service availability and is expressed as a percentage like 99,9 (colloquially ‘three-nines’, ‘four-nines’ for 99,99% and so on), but soon we will see that this is a simplification. Especially in public cloud computing, failing to meet a set SLA carries a contractual penalty for the provider and a compensation to their clients, such as refunds or discounts, so it is in a provider’s best interest to react preemptively when the software system shows signs of degradation. That brings us to Service Level Objectives (SLOs).
Service Level Objectives
Service Level Objectives are goal values you set for your software system. They are not contractually bound like SLA values, but they still define the minimum baseline for your software system to be considered functional. It is a good practice to set SLOs slightly stricter than the thresholds defined in your SLAs; if your SLA promises 99,5% availability, 99,7% SLO gives you some leeway to fix problems in your software before they manifest for your users and start incurring sanctions. Obviously, you want to detect the symptoms before you start violating your SLOs and you do that by monitoring and measuring your Service Level Indicators (SLIs).
Service Level Indicators
Service Level Indicators are metrics you collect about your software system’s health. Often coined under general term of ‘availability’, SLIs are specific technical measurements the system produces. However, what constitutes of availability and unavailability varies from system to system. Straightforward simplifications on availability such as ‘my server is on and reachable 99,9% of the time’ can easily hide symptoms of a badly behaving system. SLIs should be values that actually matter to the users and their experience with the software system.
What to measure and how?
So, general ‘availability’ is not a good enough metric. Why?
A very heavy-handed example would be an Industrial Control System (ICS) that is only used during the day when the work is done on the factory floor. However, there’s a bug in this ICS that causes random disconnections and freezes when a certain load is reached in the system. This happens frequently during the day, but never outside working hours. If you would only monitor for server health or network connectivity (instead of HTTP error codes for example), your metrics would never reveal the problem affecting your users. In this scenario it does not matter if your SLO is met as it does not give you insight to how your users interact with the systems and how they experience using it. In the worst case scenario your SLI is just plain wrong, but even a good SLI may hide bad behaviour if the measurement window is too wide.
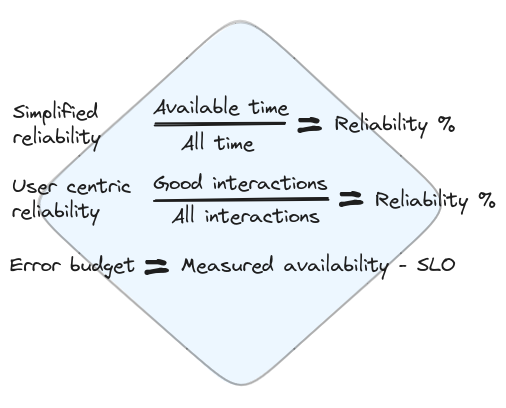
A simplistic way to measure availability is to look at the ‘good time’ your system experiences divided by total time. In the example above, you could have a health check or a liveness probe periodically checking on the server health and everything would look fine based on it. A more refined approach to measuring availability would be to measure the ratio of good interactions against the total number of interactions. Metrics like latency, error ratio, throughput and correctness might matter more to your users than just raw liveness. Server availability is the basic requirement, serving requests correctly and in a timely manner is what brings value.
As always with complex systems, there is no silver bullet to choosing correct SLIs. In some cases we could for example tolerate some number of false positives or incomplete data as long as we get it fast whereas in other cases we could be willing to tolerate a system with notable latency or subpar throughput if we can be sure that the data we get is always correct.
When you have identified your SLIs, you have to set SLOs and SLAs. As a rule of thumb, every system breaks somehow sometime. Even if you managed to build an infallible system, external forces like network congestion and hardware failure could hinder your performance. That’s why it is unrealistic to aim for 100% availability. The goals you set for your system are also not static. When developing and launching new software, you probably want to set your goals modestly for starters. As you gain more data on user interactions and loads your system experiences, you can re-evaluate the goals while you keep improving the software. This brings us to our next topic.
Why should you care about service level in software development?
I have said it before and I will say it again: software development is a customer service job. No commercial software system exists for its own sake. There are end users, your clients, who get something out of the software you build and your software should meet their needs constantly if you want to succeed. While user research might tell you what features you should build next, your service level tells how the features you already built are performing. With the ‘you build it, you run it’ approach becoming more prevalent within the industry, maintaining existing products increasingly becomes an exercise in the realms of software development processes rather than just an operational task. Best of all, monitoring your service levels allows you to make data-driven decisions when working on your software system.
I had an interesting discussion about service levels with a colleague who is managing a software team in a product company. I asked if they had SLAs and SLOs in place and he assured me they do. I also queried about their working practices and he told me they work in two week sprints building new features, but every now and then, usually after major releases, they have so-called ‘cooldown’ sprints where they work on improving the existing code base, refactoring and erasing technical debt. I said that’s just great, fantastic even. Technical debt will stifle the productivity and development speed in the long run, so I applaud any formal efforts taken trying to fight it.
Then I asked a few harder questions that revealed some room for improvement. The first one was: “What do you do if your SLOs are not being met?” He told me, that their SLOs were regarded more like key performance indicators: something they should strive for but is not actively acted upon. The second question I asked was: “How do they determine when to have a cooldown sprint”. From the answer I deduced that the decision was made somewhat at whim and when the feature backlog was not actively bursting from the seams with high priority stuff.
My main gripe with these answers is that breaking an SLO should always warrant action. If there are no procedures tied to it, an SLO becomes hollow fluff. That does not mean you should treat all SLO violations as major incidents; it is as unrealistic to expect 100% availability as it is to meet SLOs 100% of the time. Failing to meet an SLO should at least cause the software development team to stop and consider if they should prioritise their work or, say, have a cooldown sprint.
Enter error budgets. It took a while to get here from the title. One could say that error budgets are a tool and indicator on how much you can… muck around before you have to start finding out. But what are they and how do they work?
How to use error budgets in software development?
Consider your service has some availability SLO of 95% tied to a monthly aggregated SLI (which, as a side note, allows for terribly long outages of 1,52 days per month!). Now you are doing some top notch software development and consistently manage to achieve 97% availability (your software is uncooperative only some 43 minutes each day…). That means, you have 97%-95%=2% budget to do risky stuff that can break your software before you are breaking your SLO. In minutes, that is an additional 28,8 on top of the current downtime.
Now talking about doing risky things in the software development context might evoke thoughts about deploying very experimental features, prototypes or even untested changes (and if you considered that, it’s OK. It is called an intrusive thought and everyone has them), but these are quite extreme examples. One should bear in mind, that in software development any change carries inherent risk in complex interconnected systems. You can use error budgets to release more frequently and with more confidence. If you do canary deployments or A/B testing, you can roll out new features faster to a wider audience because your error budget gives you this leeway. You could plan and perform maintenance breaks knowing you will not violate your SLOs. I think one of the most important things is that you get a data-driven indicator which allows you to make informed choices when balancing between system reliability and innovating new features.
Building on the previous example, consider you introduce a new change to your software system. Everything seems fine until in a couple of days you find out that your daily downtime has gone from 43 minutes to some 58 minutes. You realise that the feature you shipped has caused some extra instability in your system and that this single feature just made a dent to your availability: from 97% to 96%. You are still not violating the SLO, but just this new feature is now taking 50% of your error budget, leaving you with less freedom to develop new features. If your outage time would have gone over 72 minutes per day, the error budget would show that you will run out of it before the end of the month: time to immediately switch over to maintenance mode before our end users start complaining!
Now you are sitting there with your error (and in a sense, development) budget cut in half, gnashing your teeth, even realising that maybe 95% SLO is not that high and some improvements must be made. What can be done before we spend the rest of our budget? That is when you should realise, that the error budget is there for you to spend! You look at your gutted budget and realise that even if you would not optimise the feature you just shipped, you could still afford 14 minutes and 24 seconds a day, or a whopping 7,2 hours per month downtime without breaking your SLOs. Encouraged, you and your team of developers and operations people (hopefully a somewhat overlapping group) can schedule a safe and informed downtime where you perform some much needed reliability improvements.
In conclusion
When building and serving software you care both about evolving it, but also about its availability and reliability. Focusing too much on the former can result in software robust on features, but brittle in architecture and maintainability, eventually slowing down the development as the majority of time is spent firefighting yet another failure. Focusing too much on the latter grinds the development to a halt as the best way to ensure reliability is to avoid making changes.
Using Service Level Agreements, Objectives and Indicators and Error Budgets effectively in your software development process enables you to strike the right balance between change versus stability. They define common goals to your developers and operations, promoting co-operation and data-driven decision making. They give your teams more ownership and agenda over the products they build and make it easier to react to problems before they can take effect.
I also did a talk at DevOps Finland on this topic, Service Levels, Error budgets, and why your dev teams should care.
If you need help optimising your software development and continuous delivery processes, don’t hesitate to get in contact with us!