How to build dashboards of your Kubernetes cluster with Steampipe

In this blog post we will take a look at Steampipe, starting with some basics and then getting into more practical examples. We’ll be querying a Kubernetes cluster with Steampipe and then building a dashboard out of our queries that can be shared amongst colleagues or even publicly in the Steampipe hub.
What is Steampipe?
Steampipe is an open source tool that can be used to query all kinds of APIs using an unified language for the queries; SQL. The core purpose of a tool like Steampipe is to answer questions. These questions might be related to compliance, security, cloud costs or operations. When operating in a cloud environment a lot of questions can be answered by querying the API, and with Steampipe we can use a unified language (SQL) to make those queries without worrying about the underlying APIs and their differences.
Querying APIs with SQL - What? How?
Steampipe uses PostgreSQL Foreign Data Wrappers under the hood to grab data from various APIs/other sources and store it in an embedded Postgres database. Steampipe uses plugins to provide support for the various sources, and at the time of writing there are over 100 plugins available for various services (LDAP, DNS etc.), types of files (CSV, JSON etc.) and APIs. But as a user of the tool, you don’t really need to know what goes under the hood, but it sure feels a bit like magic writing an SQL query against the Kubernetes API which we will get into next.
Practical Introduction to Steampipe
Let’s roll up our sleeves and write some SQL to learn more about the tool! To follow along with these steps, spin up a local Kubernetes cluster using tool such as k3d, kind or minikube. Or spin up a cluster in your favourite cloud, it does not matter what kind of a cluster it is to follow along.
Setting up Steampipe
First things first, we must install steampipe. Follow the official documentation for your operating system: https://steampipe.io/downloads
After installing the CLI, install also the Kubernetes plugin:
steampipe plugin install kubernetes
First Query
Now you can start querying your cluster. You can run the following command to enter an interactive session within your terminal:
steampipe query
Try running a query, for example:
select name, namespace from kubernetes_pod;
Note that the first query might take a while to run when steampipe has to initialise the database. In my kind cluster this returns a following result:
+----------------------------------------------------+--------------------+
| name | namespace |
+----------------------------------------------------+--------------------+
| coredns-5d78c9869d-2q9pl | kube-system |
| kube-controller-manager-kind-cluster-control-plane | kube-system |
| envoy-ngv2z | projectcontour |
| kube-proxy-jqr75 | kube-system |
| coredns-5d78c9869d-t286f | kube-system |
| kube-apiserver-kind-cluster-control-plane | kube-system |
| etcd-kind-cluster-control-plane | kube-system |
| local-path-provisioner-6bc4bddd6b-kqr22 | local-path-storage |
| contour-d8c6f457f-h4skq | projectcontour |
| contour-d8c6f457f-nj5qh | projectcontour |
| kube-scheduler-kind-cluster-control-plane | kube-system |
| kindnet-gszzf | kube-system |
| contour-certgen-v1.24.2-zfnhj | projectcontour |
+----------------------------------------------------+--------------------+
Another useful command is .inspect which is one the steampipe meta-commands, it lists all the columns and their types and description:
> .inspect kubernetes_pod
+----------------------------------+--------------------------+-------------------------------------------------------------------------------+
| column | type | description |
+----------------------------------+--------------------------+-------------------------------------------------------------------------------+
| _ctx | jsonb | Steampipe context in JSON form, e.g. connection_name. |
| active_deadline_seconds | text | Optional duration in seconds the pod may be active on the node relative to St |
| | | artTime before the system will actively try to mark it failed and kill associ |
| | | ated containers. |
| affinity | jsonb | If specified, the pod's scheduling constraints.
...
You can also run queries without entering the interactive mode, for example:
steampipe query "select name, namespace from kubernetes_pod;"
Asking Questions
As stated previously, the core purpose of a tool like Steampipe is to answer questions. Let’s come up with an example question and then use Steampipe to provide the answer.
A while back the Kubernetes project announced that they are deprecating the k8s.gcr.io registry in favour of registry.k8s.io, you can read more about this change from these links:
- https://kubernetes.io/blog/2022/11/28/registry-k8s-io-faster-cheaper-ga/
- https://kubernetes.io/blog/2023/03/10/image-registry-redirect/
Let’s use this announcement as an example to form a question; is my cluster affected by this change upstream? Or in other words; is the k8s.gcr.io registry used in my cluster?
Let’s deploy one of the example applications provided by the Kubernetes project itself that uses images from the registry we’re interested in:
git clone https://github.com/kubernetes/examples.git
cd examples
First, let’s checkout an old commit where the images are still pulled from k8s.gcr.io, which has been changed in the current HEAD:
git checkout 4d12a8ba1b8e219069ece32a9d804885f6dcc56c
Second, let’s apply this to a new namespace in the cluster:
kubectl create namespace guestbook
kubectl apply -f guestbook-go/ -n guestbook
kubectl get pods -n guestbook
Third, let’s see if we can find any pods using the legacy registry now in the cluster:
steampipe query "select name, namespace, c ->> 'image' as image from kubernetes_pod, jsonb_array_elements(containers) as c where c ->> 'image' like 'k8s.gcr.io/%'"
We should see some results, but looking at the results in our terminal isn’t always the ideal way of digesting information, especially if we haven’t authored the query. Luckily Steampipe has a lot more tricks up it’s sleeve to turn the query results into something easier to digest at a glance. Next, we will take a peak at one of the key features of Steampipe, at least in my opinion, dashboards!
Building a Dashboard
Dashboards are written in text files using the HashiCorp Configuration Language (HCL). This makes it really easy to go from a query into a visual presentation that can be shared amongst the organisation. Let’s take the earlier queries and create a small dashboard out of them.
First Dashboard
Before creating the dashboard we will have to initialize a new Steampipe mod, mods are a way to package a collection of Steampipe queries/dashboards etc. to a package that can be shared, for example in Steampipe hub.
First we create an empty directory and then initialize the mod inside of the directory:
mkdir k8s-dashboard
cd k8s-dashboard
steampipe mod init
This will create a mod.sp file that looks like this:
mod "local" {
title = "k8s-dashboard"
}
Now we can move on to actually creating the dashboard. First, let’s create a dashboard resource in an empty file:
dashboard "k8s_dashboard" {
title = "Awesome Kubernetes Dashboard"
tags = {
type = "Dashboard"
}
}
Now before even running this, let’s add our first query which will show a card in the dashboard. Let’s use the query from earlier to list pods in all namespaces, but we will modify the SELECT statement a bit so that Steampipe knows how to interpret the query results:
dashboard "k8s_dashboard" {
title = "Awesome Kubernetes Dashboard"
tags = {
type = "Dashboard"
}
card {
sql = <<-EOQ
select
count(name) as value,
'Number of Pods' as label
from
kubernetes_pod;
EOQ
width = 3
}
}
Now we can run a command to open up the dashboard in our browser:
steampipe dashboard
After running the command, Steampipe will try to open your default browser. Click on the link of the dashboard and you will see the card there:
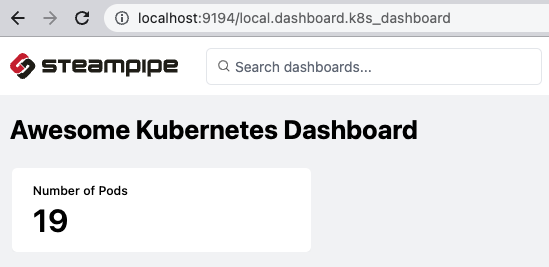
That was easy, but not very visual yet. I think we can do be better with little additional effort.
Enhancing the Dashboard
Let’s add couple more things to play with the dashboard, you can leave the steampipe dashboard command running in the background and open up the file for editing, the dashboard will automatically reload.
Let’s add a donut chart that show the number of pods grouped by namespace:
chart {
type = "donut"
title = "Pods per namespace"
width = 6
sql = <<-EOQ
select
namespace as Namespace,
count(name) as Total
from
kubernetes_pod
group by
namespace
order by
Total
EOQ
}
We can also add text and by default Steampipe supports markdown:
text {
value = <<-EOM
# Heading
**NOTE:** markdown is supported
EOM
}
Note that both the chart and the text resources should be inside the dashboard resource. Here’s how the file should look so far:
dashboard "k8s_dashboard" {
title = "Awesome Kubernetes Dashboard"
tags = {
type = "Dashboard"
}
text {
value = <<-EOM
# Heading
**NOTE:** markdown is supported
EOM
}
card {
sql = <<-EOQ
select
count(name) as value,
'Number of Pods' as label
from
kubernetes_pod;
EOQ
width = 3
}
chart {
type = "donut"
title = "Pods per namespace"
width = 6
sql = <<-EOQ
select
namespace as Namespace,
count(name) as Total
from
kubernetes_pod
group by
namespace
order by
Total
EOQ
}
}
And, the dashboard should look like this now:
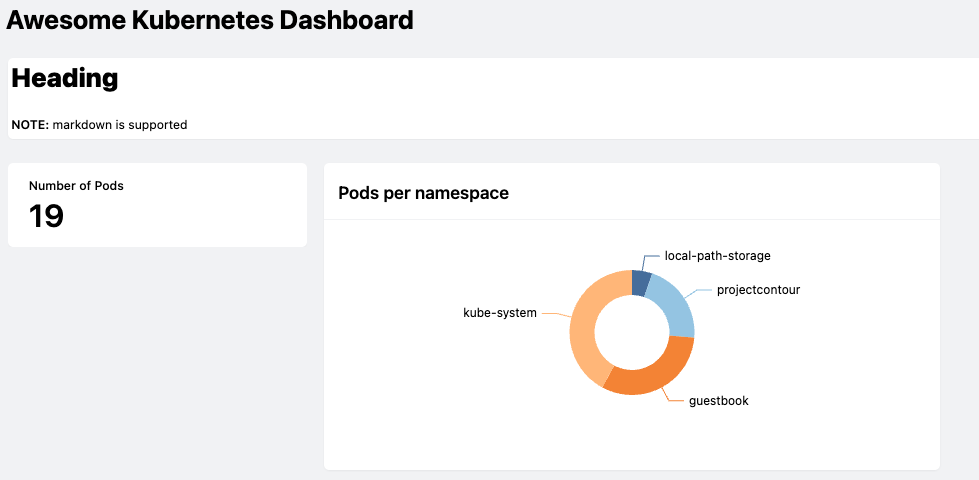
Let’s also add the query from before to find all the pods using the legacy container registry, for this we will create a card and a table. Idea is that the card will provide us visibility with a quick glance if we’re affected, to make this really pop we will set the type column to alert if the count of pods is not 0:
query "pods_using_legacy_registry_card" {
sql = <<-EOQ
select
count(name) as value,
'Pods Using Legacy Registry' as label,
case count(name) when 0 then 'ok' else 'alert' end as type
from
kubernetes_pod,
jsonb_array_elements(containers) as c
where
c ->> 'image' like 'k8s.gcr.io/%'
EOQ
}
Setting the type to alert has the effect of making the card red. You should also note that the above resource is a query resource instead of a card or a table . Using query resources helps to keep the file a bit more organised.
Also note that the query resource should not be placed inside the dashboard resource.
Instead of writing the query inline like previously, we can refer to a query resource in a card inside a dashboard like this:
card {
query = query.pods_using_legacy_registry_card
width = 3
}
You can also refer to queries across different files etc. allowing some level of re-use, but not across different types of visualisations since the queries will be bit different. That is why for a table we will define another query:
query "pods_using_legacy_registry_table" {
sql = <<-EOQ
select
name as Name,
namespace as Namespace,
c ->> 'image' as Image
from
kubernetes_pod,
jsonb_array_elements(containers) as c
where
c ->> 'image' like 'k8s.gcr.io/%'
EOQ
}
And then a table that references the query:
table {
query = query.pods_using_legacy_registry_table
}
It’s probably good to add a text resource too as a separator, to be placed above the new resources:
text {
value = <<-EOM
# Containers using k8s.gcr.io
EOM
}
We can append the new text, card and table to the dashboard like this for example:
dashboard "k8s_dashboard" {
title = "Awesome Kubernetes Dashboard"
tags = {
...
}
text {
...
}
card {
...
}
chart {
type = "donut"
title = "Pods per namespace"
...
}
text {
value = <<-EOM
# Containers using k8s.gcr.io
EOM
}
card {
query = query.pods_using_legacy_registry_card
width = 3
}
table {
query = query.pods_using_legacy_registry_table
}
}
query "pods_using_legacy_registry_card" {
...
}
query "pods_using_legacy_registry_table" {
...
}
Putting these new pieces together should look something like the below screenshot (scroll a bit further down to find the finalised dashboard):
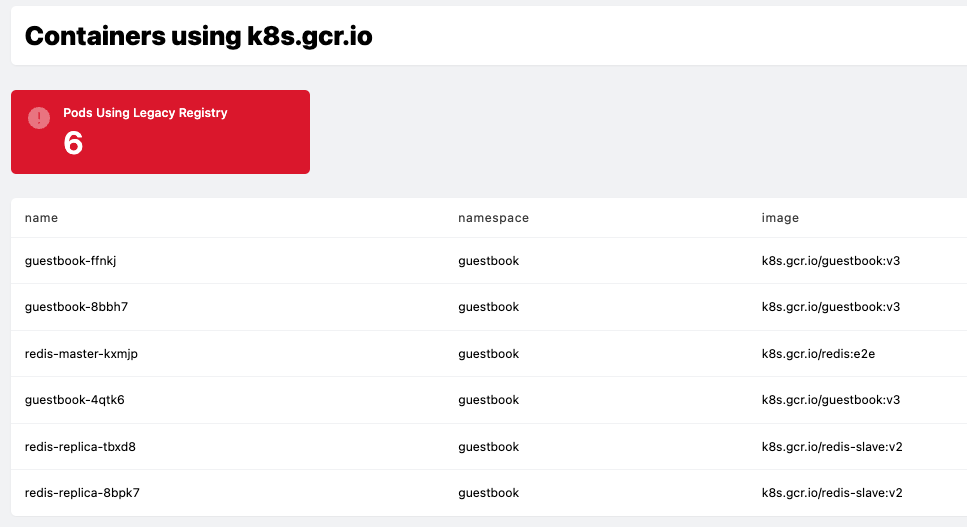
Having the table and card together allows us to immediately drill-down for more information without leaving the browser. This is also a nice way of sharing information to stakeholders that might not have access to the cluster directly.
Putting it together
Here’s the final dashboard:
dashboard "k8s_dashboard" {
title = "Awesome Kubernetes Dashboard"
tags = {
type = "Dashboard"
}
text {
value = <<-EOM
# Heading
**NOTE:** markdown is supported
EOM
}
card {
sql = <<-EOQ
select
count(name) as value,
'Number of Pods' as label
from
kubernetes_pod;
EOQ
width = 3
}
chart {
type = "donut"
title = "Pods per namespace"
width = 6
sql = <<-EOQ
select
namespace as Namespace,
count(name) as Total
from
kubernetes_pod
group by
namespace
order by
Total
EOQ
}
text {
value = <<-EOM
# Containers using k8s.gcr.io
EOM
}
card {
query = query.pods_using_legacy_registry_card
width = 3
}
table {
query = query.pods_using_legacy_registry_table
}
}
query "pods_using_legacy_registry_card" {
sql = <<-EOQ
select
count(name) as value,
'Pods Using Legacy Registry' as label,
case count(name) when 0 then 'ok' else 'alert' end as type
from
kubernetes_pod,
jsonb_array_elements(containers) as c
where
c ->> 'image' like 'k8s.gcr.io/%'
EOQ
}
query "pods_using_legacy_registry_table" {
sql = <<-EOQ
select
name as Name,
namespace as Namespace,
c ->> 'image' as Image
from
kubernetes_pod,
jsonb_array_elements(containers) as c
where
c ->> 'image' like 'k8s.gcr.io/%'
EOQ
}
Summary
We’ve only scratched the surface of what is possible with Steampipe in this blog, maybe we will explore more features and plugins in future blog posts. We highly recommend checking out the project. Even if your SQL is rusty, we find it’s quite easy to get things done and after a bit of practice you’ll find yourself writing queries ad-hoc to answer questions that pop up.
If you found something wrong with the content or something felt vague or awesome, leave us a comment! Additionally, if you’d like any help with Steampipe and/or Kubernetes please get in touch!